
如何從需求的條件寫出SQL指令?
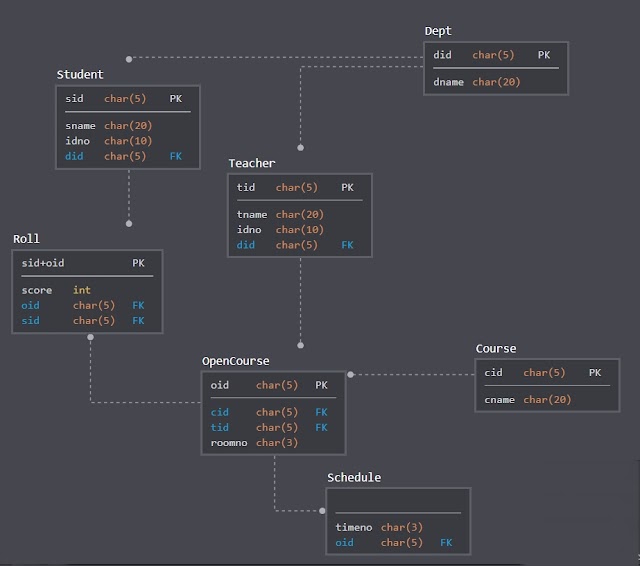
需求~要列出符合【某個條件】的【某項資料】,應該如何寫出SQL指令呢? 第一步 : 找齊資料表。 【某項資料】是在哪個資料表? 以及【某個條件】中的判斷條件是在哪個資料表? 所以這個步驟 ,就可以把資料表都找齊了。 第二步 : 篩選出來【正確的資料表】。 但是許多情況,【某項資料】會存在許多資料表中,這個時候就要判斷,哪個資料表才是正確的。 方法就是把第一步找到的資料表,畫出關聯性,【某項資料】一定會存在具有關聯性的資料表中。所以就可以把不在關聯的資料表刪除。 第三步 : 套用再調整。 套用 SELECT 【某項資料】 FROM 【正確的資料表】 WHERE 【某個條件】AND 主鍵外鍵的關聯 其他部分 (如GROUP BY、HAVING、ORDER BY等等) 調整 看看那些欄位需要冠上 ~ 資料表.資料欄,例如 學生資料表.學生姓名 例如~ 要列出開課編號為o0001的「開課編號」、「學生姓名」。 由第一步,相關的欄位是 「 開課編號 」 、「學生姓名」。 「學生姓名」存在於學生資料庫, 「 開課編號 」存在於 選課資料表、 開課資料表、 時間資料表。 由第二 步,學生資料庫與 選課資料表,透過 學生編…


資料庫的好處有哪些?
資料庫的好處有哪些? (1) 達成資料的一致性 (Data Consistency) 例如如果學號A0001的學生,姓名從「王曉明」改為「王大明」,則所有地方抓出學號A0001的學生,姓名都會是「王大明」。 (2) 達成資料的共享性 (Data Sharing) 指同一份資料可以共享給多個人員或是應用程式。 (3) 達成資料的獨立性 (Data Independence) 資料與應用程式是分開的,修改應用程式並不會影響資料。 (4) 達成資料的完整性 (Data Integrity) 例如當資料不能刪除時,不會因為操作錯誤而引起錯誤。也就是資料會因為其間的關聯,而維持應該有的關係。 (5) 達成資料的安全性 (Data Security) 例如資料可以加密,或是可以分為不同權限等。 (6) 降低資料的重複性 (Redundancy) 不需要相同資料一再出現,只需要關聯即可。 (7) 避免紙張的浪費 (Paper Waste) 可以數位式儲存,不需要列印出來。

SQL commands of DML (Data Manipulation Language)
DML (Data Manipulation Language)的SQL commands有: (1) SELECT ~ retrieve data from the a database 語法: SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] select_expr [, select_expr ...] [FROM table_references [WHERE where_condition] [GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]] [HAVING where_condition] [ORDER BY {col_na…

SQL commands of DDL (Data Definition Language)
DDL (Data Definition Language) 的SQL commands有: (1)CREATE - to create objects in the database 建立資料庫(database) 語法: CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [create_specification] ... create_specification: [DEFAULT] CHARACTER SET [=] charset_name | [DEFAULT] COLLATE [=] collation_name 更多參考: http://dev.mysql.com/doc/refman/5.0/en/create-database.html 例如: CREATE DATABASE mydatabase; 或是 CREATE DATABASE mydatabase CHARACTER SET big5 COLLATE big5_chinese_ci ; 或是 CREATE DATABASE mydatabase CHARACTER SET utf8 CO…


