MYSQL DDL (Data Definition Language)
(1) CREATE DATABASE 範例 CREATE DATABASE dbname; 範例 CREATE DATABASE dbname CHARACTER SET utf8 COLLATE utf8_general_ci; (2) CREATE TABLE 範例 CREATE TABLE mytable (field1 CHAR(10), field2 INT(10)) ; 範例 CREATE TABLE customer ( cus_id int NOT NULL, cus_name varchar(255) NOT NULL, cus_address varchar(255), cus_no char(3), PRIMARY KEY (cus_id) ); 範例 CREATE TABLE A LIKE B; ~ 此種方式在將表復制到A時候會將表B完整的字段結構和索引復制到表A中來。 範例 CREATE TABLE A AS SELECT x,x,x,xx FROM B LIMIT 0; ~ 此種方式只會將表B的字段結構復制到表A中來,但不會復制表B中的索引到表A中來。這種方式比較靈活可以在復制原表表結構的…

資料庫正規化實作練習
如下的資料,我們應該如何進行正規化呢? 如果無正規化,對於處理上有何問題呢? 資料表1: 問題在於欄位並非atomic(基元值),學號、學生姓名、成績欄位中有多個數值,所以並不符合1NF的條件。改成資料表3,所有記錄中的項目都是基元值,即無重覆資料項目,就可符合1NF的條件。 資料表2: 問題在於無法決定學生1、學生2、學生3 ... 到底需要多少個欄位,成績亦同,所以這個資料表無法決定相依關係。 資料表3: 問題在於不符合2NF的條件,也就是每一個非鍵屬性無法完全相依於主鍵。 所以必須拆開成幾個表單~ 如資料表4,以符合2NF的條件。 課程資料表 ( 課程編號 , 課程名稱, 教師編號, 教師姓名) , 學生資料表 ( 學號 , 學生姓名) , 成績資料表 ( 課程編號 , 學號 , 成績)。 資料表4: 但是上面的課程資料表,尚不符合3NF,所以再拆成如下資料表5。 資料表5: 所以就得到 .... 課程資料表 ( 課程編號 , 課程名稱, 教師編號) , 老師資料表 ( 教師編號 , 教師姓名) , 學生資料表 ( 學號 , 學生姓名) , 成績資料表 ( 課程編號, 學號 , …

從ER Model到資料庫的實作練習
ER模型 全名為實體關聯模型或實體關係模型或實體關聯模式圖(Entity-relationship model,Entity-relationship Diagram),由美籍華裔計算機科學家陳品山發明,是概念數據模型的高層描述所使用的數據模型或模式圖,它為表述這種實體聯繫模式圖形式的數據模型提供了圖形符號。 參考: 實體關係模型(Entity-relationship model) 從ER Model到資料庫的形成步驟為:(1)需求分析 (2)ER Model (3)邏輯資料庫 (4)實體資料庫。但是這些步驟並非標準答案,有些可能簡化成步驟(1)(2)(4),也有些更細分出更多步驟。不過不管如何,ER Model都是從需求到資料庫形成的重要步驟。 假設現在需要設計學生選課系統,我們由四大步驟來看看過程。 (1)需求分析 ~ 我們與使用者訪談的結果,得到以下幾個需求 (a)每位專任老師在不衝堂下,可以開設多門課程。 (b)相同課程只能有一位老師開課。 (c)每個課程只要有10位以上同學修課,即可以開課。 (d)每個課程必須有一間不衝堂的教室。 (e)每位學生可以修多門課程,學分上下限為24與9學分。 (f)每個課程需依照教室可容納人數以限制修課人數…

SELECT : 從資料表中擷取資料
語法 SELECT [fields list] FROM [tables list] JOIN [tables] ON [conditions] WHERE [conditions] GROUP BY [columns] HAVING [conditions] ORDER BY [columns] (1) 從product資料表中, 擷取prod_id與prod_name的資料 SELECT prod_id, prod_name FROM product; (2) 從product, customer資料表中, 擷取prod_name與cus_name的資料 SELECT product.prod_name, customer.cus_name FROM product, customer; 但是這樣子的指令會產生什麼結果呢? 這是product, customer的資料 但是以 SELECT product.prod_name, customer.cus_name FROM product, customer; 之後的資料如下圖 如果以 SELECT product.prod_name, cu…

實作練習 (續)
在 實作練習 中,我們建立了四個表單,各是~ 客戶資料表 (customer)、產品資料表(product)、訂單表頭資料表(order_head)、訂單表身資料表(order_body)。 現在我們來練習SQL command的SELECT用法。 SELECT [fields list] FROM [tables list] JOIN [tables] ON [conditions] WHERE [conditions] GROUP BY [columns] HAVING [conditions] ORDER BY [columns] (1) 列出客戶資料表 (customer)中的所有客戶代號、客戶名稱。 SELECT cus_no, cus_name FROM customer; (2) 找到客戶代號為c01的客戶地址。 SELECT cus_address FROM customer WHERE cus_no='c01'; (3) 找到客戶名稱中存在"科技"字串的所有客戶地址。 SELECT cus_address FROM customer WHERE cus_name like '…

MYSQL的time, datetime, timestamp
MYSQL的time, datetime, timestamp都是時間類型的資料型態,但是有些微的差異: 當你需要日期加上時間,則使用datetime~ 範圍由'1000-01-01 00:00:00'到'9999-12-31 23:59:59' 當你只需要時間,則使用time~ 範圍由'00:00:00'到'23:59:59' 當你只需要日期,則使用date~ 範圍由'1000-01-01'到'9999-12-31' timestamp則是日期戳章,例如你可以透過SELECT CURRENT_TIMESTAMP(); 看到現在目前的日期戳章。timestamp經常用來當作自動插入的欄位,例如你可以宣告 myautotimestamp TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP 那麼這個myautotimestamp不需要給資料,就會自動把目前的日期戳章插入。 但是在timestampe中,還分成兩種format,一種如'1365647419'這樣,另一種如'2013-04-11…

實作練習
我們希望可以完成如下的表單 (1) 先建立新的資料庫 (紅色部分依你的需求更改) 建立資料庫,名稱為 newdbname 並且使用字元集為 utf8,排序規則是 utf8_general_ci (不分大小寫)。 參考資料: 如何使用指令知道資料庫的字元集和排序規則? MySQL CHARACTER SET 與 COLLATION create database newdbname character set utf8 collate utf8_general_ci; (2) 開始使用 newdbname 這個資料庫。 use newdbname ; (3) 建立資料表單 customer CREATE TABLE customer ( cus_id int NOT NULL, cus_name varchar(255) NOT NULL, cus_address varchar(255), cus_no char(3), PRIMARY KEY (cus_id) ); 參考資料(Create): https://www.mysql.tw/2013/03/sql-commands-of-ddl-data-defi…

SQL PRIMARY KEY Constraint
你可以在建立表單時宣告主鍵(primary key),也可以使用ALTER TABLE來建立或是刪除。 CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (P_Id) ); 你也可以使用以下指令來建立: CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), CONSTRAINT pk_PersonID PRIMARY KEY (P_Id) ); 如果Primary key是多欄組成: CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName va…
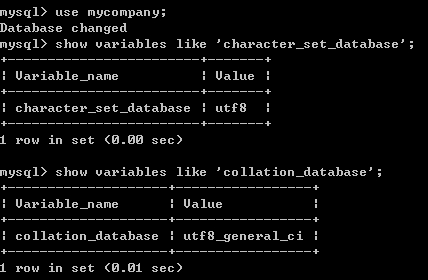
如何使用指令知道資料庫的字元集和排序規則?
假設我們以如下指令新建一個資料庫 CREATE DATABASE mytable CHARACTER SET utf8 COLLATE utf8_general_ci ; 那麼我們就產生了一個資料庫 mytable,並且字元集是 utf8 ,以 utf8_general_ci為排序規則。 但是建立完成之後,過陣子我萬一忘記了字元集跟排序規則的設定,我可以從哪裡知道呢? 你可以使用指令知道資料庫的字元集和排序規則,如下圖。 (1) 你先使用 use mycompany; 開始使用該資料庫。 (2) 以指令 show variables like 'character_set_database' ; 把 mycompany 的字元集資料叫出來。你就看到了字元集是 utf8。 (3) 以指令 show variables like 'collation_database' ; 把 mycompany 的排序規則資料叫出來。你就看到了排序規則是 utf8_general_ci。