實作練習~公司員工訂餐系統
某公司希望設計一個提供員工中午訂餐的服務,該系統需求如下: (1)該系統有數個餐廳的餐點提供員工點餐。 (2)該系統在每天早上讓員工線上點餐。 (3)為方便結帳,該系統採用預付制,也就是先存錢給秘書,然後依照訂餐扣款。 (4)希望每個訂餐依照所訂購的每位同事帳戶下扣款。 (5)每個每個人可以訂購多項餐點,也可以跨不同餐廳訂購。 (6)員工帳戶資料要能夠記載預付時間、金額,以及扣款時間、金額及對應的餐點。 (7)該系統必須能夠提供每位員工統計報告,記載每月的餐費。 (8)該系統必須能夠統計各餐廳/餐點的消費紀錄,以便知道員工對於餐廳/餐點的喜好。 該系統的 ERD應該如何設計呢? 該系統的實際資料庫應該如何設計呢? 步驟一: 先找出物件 (Entity) 員工(Employee)、餐廳(Restaurant)、餐點(Item)、帳戶(Account)、帳戶紀錄(Account Log)、訂單(Order)、訂單紀錄(Order Item),我們也可以再多出一個部門物件,以紀錄員工的部門。 所以總共八個物件。 步驟二: 再找出物件間的關係 (Relationship) 餐廳(Restaurant) --> 餐點(Item) 員工(E…

實作練習 ~ 選課資料
我們在" 從ER Model到資料庫的實作練習 ",了解從ER Model到資料庫的形成步驟,現在來進行實際的實體資料庫建立。 假設資料庫的關聯及結構如下圖 (下圖是以Access的工具製作而成): 其邏輯資料庫可以表示如下: 課程資料表 course( cid ,cname,credit,tid) 老師資料表 teacher( tid ,tname,tarea) 學生資料表 student( sid ,sname,did) 科系代碼表 department( tid ,tname,tboss) 選課資料表 enrollment( sid , cid ,score) 學務處資料表 score1( serial ,sid,score) 教務處資料表 score2( serial ,sid,score) 但是這個資料庫結構設計有些問題: (1)沒有表示年度與學期 (2)教務處資料表的學業成績是甚麼? (3)課程資料表是用來給學生選課,應該分成~課程基本資料表+開課資料表 所以我們將之更新如下: 課程基本資料表 course( cid ,cname,credit,ctype,did) 開課資料表 cour…

SQL語法中WHERE與HAVING有何差異?
SQL語法中WHERE與HAVING有何差異? 這兩個都是在進行資料的過濾,但是在使用上是有差別的。 在SQL語法中,我們可以使用WHERE給予條件,進行資料的過濾,例如有如下資料表: 我們使用 SELECT * FROM mymoney WHERE mamount>1000; 如下,資料只顯示出金額大於1000的資料列。 但是如果我們使用 SELECT * FROM mymoney HAVING mamount>1000; 雖然沒有錯誤,但是就不是好的語法了。 為何呢? 因為HAVING只能用在aggregate (合計) 情況下 ,也就是有GROUP BY的時候,並且HAVING要過濾的條件,要跟GROUP BY的合計函數有關。 例如我們來看以下範例: SELECT SUM(mamount) FROM mymoney WHERE SUBSTR(mdate,1,6)='201401'; 列出符合201401條件的金額加總,如上列出75500。 SELECT SUM(mamount) FROM mymoney WHERE SUBSTR(mdate,1,6)=&#…
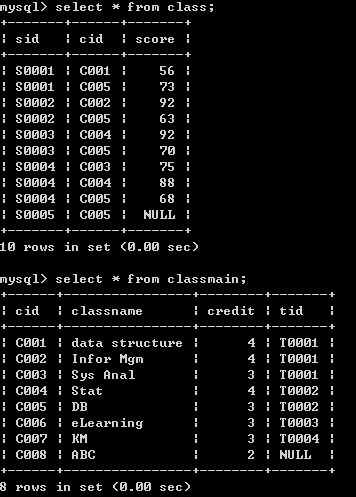
SQL SELECT語法整理
假設有以下資料表 class, classmain, teacher, student, dept, tea, stud ~ (1) SELECT * FROM CLASS; (2) SELECT sid, cid FROM CLASS; (3) SELECT sid AS s, cid AS c FROM CLASS; (4) 模擬SELECT INTO語法 (MYSQL不支援SELECT INTO) INSERT INTO myclass (class_no,class_name) SELECT cid, classname FROM classmain; (5) SELECT * FROM classmain WHERE cid>'C004'; (6) SELECT * FROM class WHERE score>60 AND cid='C005'; (7) SELECT * FROM class WHERE cid='C005' AND NOT score>60; (8) SELECT * FROM class WHERE score …

資料表單的運算
在關聯式代數中,有以下幾種不同的運算: -- 限制 (Restrict) ~ 選取符合某些條件的值組(記錄),另成一個新的關聯表。 例如: SELECT * FROM tableA WHERE [conditions] -- 投影 (Project) ~ 選取想要的欄位(屬性),另成一個新的關聯表。 例如: SELECT [some fields] FROM tableA -- 卡氏積 (Cartesian Product) ,又稱Cross Product(交叉乘積)、Cross Join(交叉合併) ~ 將兩個關聯表相乘,形成一個新的關聯表。但是光是關聯表相乘,並不是我們真正需要的,所以通常相乘後,都還需要加上另外的條件。 例如: SELECT * FROM tableA, tableB 或是: SELECT * FROM tableA CROSS JOIN tableB 上面兩個表示法,得到的結果是相同的。 例如兩個表單 student (五筆資料) 與 class (十筆資料) ,資料表內容如下: 我們以SELECT * FROM student, class; 及SELECT * FROM student CROSS JOIN…

實作練習
(1)建立資料庫 create database myhome character set utf8 collate utf8_general_ci; 建立mycategory CREATE TABLE mycategory ( cid char(3) NOT NULL, cname varchar(30), cflag char(1), PRIMARY KEY (cid) ); 建立mymoney CREATE TABLE mymoney ( mid char(10) NOT NULL, cid char(3) NOT NULL, mdate char(8), mamount int(7), mperson char(1), PRIMARY KEY (mid) ); (2)歲末時想知道今年每個月的汽油費用開銷多少,應該如何寫出SQL? select sum(mamount) from mymoney where cid='003' group by substr(mdate,1,6); ※如果要知道「每年 汽油費用開銷多少 」,應該如何寫SQL呢? (3)歲末時要知道今年每個月的收支狀況,應該如何寫…

MYSQL DDL (Data Definition Language)
(1) CREATE DATABASE 範例 CREATE DATABASE dbname; 範例 CREATE DATABASE dbname CHARACTER SET utf8 COLLATE utf8_general_ci; (2) CREATE TABLE 範例 CREATE TABLE mytable (field1 CHAR(10), field2 INT(10)) ; 範例 CREATE TABLE customer ( cus_id int NOT NULL, cus_name varchar(255) NOT NULL, cus_address varchar(255), cus_no char(3), PRIMARY KEY (cus_id) ); 範例 CREATE TABLE A LIKE B; ~ 此種方式在將表復制到A時候會將表B完整的字段結構和索引復制到表A中來。 範例 CREATE TABLE A AS SELECT x,x,x,xx FROM B LIMIT 0; ~ 此種方式只會將表B的字段結構復制到表A中來,但不會復制表B中的索引到表A中來。這種方式比較靈活可以在復制原表表結構的…

資料庫正規化實作練習
如下的資料,我們應該如何進行正規化呢? 如果無正規化,對於處理上有何問題呢? 資料表1: 問題在於欄位並非atomic(基元值),學號、學生姓名、成績欄位中有多個數值,所以並不符合1NF的條件。改成資料表3,所有記錄中的項目都是基元值,即無重覆資料項目,就可符合1NF的條件。 資料表2: 問題在於無法決定學生1、學生2、學生3 ... 到底需要多少個欄位,成績亦同,所以這個資料表無法決定相依關係。 資料表3: 問題在於不符合2NF的條件,也就是每一個非鍵屬性無法完全相依於主鍵。 所以必須拆開成幾個表單~ 如資料表4,以符合2NF的條件。 課程資料表 ( 課程編號 , 課程名稱, 教師編號, 教師姓名) , 學生資料表 ( 學號 , 學生姓名) , 成績資料表 ( 課程編號 , 學號 , 成績)。 資料表4: 但是上面的課程資料表,尚不符合3NF,所以再拆成如下資料表5。 資料表5: 所以就得到 .... 課程資料表 ( 課程編號 , 課程名稱, 教師編號) , 老師資料表 ( 教師編號 , 教師姓名) , 學生資料表 ( 學號 , 學生姓名) , 成績資料表 ( 課程編號, 學號 , …

從ER Model到資料庫的實作練習
ER模型 全名為實體關聯模型或實體關係模型或實體關聯模式圖(Entity-relationship model,Entity-relationship Diagram),由美籍華裔計算機科學家陳品山發明,是概念數據模型的高層描述所使用的數據模型或模式圖,它為表述這種實體聯繫模式圖形式的數據模型提供了圖形符號。 參考: 實體關係模型(Entity-relationship model) 從ER Model到資料庫的形成步驟為:(1)需求分析 (2)ER Model (3)邏輯資料庫 (4)實體資料庫。但是這些步驟並非標準答案,有些可能簡化成步驟(1)(2)(4),也有些更細分出更多步驟。不過不管如何,ER Model都是從需求到資料庫形成的重要步驟。 假設現在需要設計學生選課系統,我們由四大步驟來看看過程。 (1)需求分析 ~ 我們與使用者訪談的結果,得到以下幾個需求 (a)每位專任老師在不衝堂下,可以開設多門課程。 (b)相同課程只能有一位老師開課。 (c)每個課程只要有10位以上同學修課,即可以開課。 (d)每個課程必須有一間不衝堂的教室。 (e)每位學生可以修多門課程,學分上下限為24與9學分。 (f)每個課程需依照教室可容納人數以限制修課人數…