實作練習 (續)
在 實作練習 中,我們建立了四個表單,各是~ 客戶資料表 (customer)、產品資料表(product)、訂單表頭資料表(order_head)、訂單表身資料表(order_body)。 現在我們來練習SQL command的SELECT用法。 SELECT [fields list] FROM [tables list] JOIN [tables] ON [conditions] WHERE [conditions] GROUP BY [columns] HAVING [conditions] ORDER BY [columns] (1) 列出客戶資料表 (customer)中的所有客戶代號、客戶名稱。 SELECT cus_no, cus_name FROM customer; (2) 找到客戶代號為c01的客戶地址。 SELECT cus_address FROM customer WHERE cus_no='c01'; (3) 找到客戶名稱中存在"科技"字串的所有客戶地址。 SELECT cus_address FROM customer WHERE cus_name like '…

MYSQL的time, datetime, timestamp
MYSQL的time, datetime, timestamp都是時間類型的資料型態,但是有些微的差異: 當你需要日期加上時間,則使用datetime~ 範圍由'1000-01-01 00:00:00'到'9999-12-31 23:59:59' 當你只需要時間,則使用time~ 範圍由'00:00:00'到'23:59:59' 當你只需要日期,則使用date~ 範圍由'1000-01-01'到'9999-12-31' timestamp則是日期戳章,例如你可以透過SELECT CURRENT_TIMESTAMP(); 看到現在目前的日期戳章。timestamp經常用來當作自動插入的欄位,例如你可以宣告 myautotimestamp TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP 那麼這個myautotimestamp不需要給資料,就會自動把目前的日期戳章插入。 但是在timestampe中,還分成兩種format,一種如'1365647419'這樣,另一種如'2013-04-11…

實作練習
我們希望可以完成如下的表單 (1) 先建立新的資料庫 (紅色部分依你的需求更改) 建立資料庫,名稱為 newdbname 並且使用字元集為 utf8,排序規則是 utf8_general_ci (不分大小寫)。 參考資料: 如何使用指令知道資料庫的字元集和排序規則? MySQL CHARACTER SET 與 COLLATION create database newdbname character set utf8 collate utf8_general_ci; (2) 開始使用 newdbname 這個資料庫。 use newdbname ; (3) 建立資料表單 customer CREATE TABLE customer ( cus_id int NOT NULL, cus_name varchar(255) NOT NULL, cus_address varchar(255), cus_no char(3), PRIMARY KEY (cus_id) ); 參考資料(Create): https://www.mysql.tw/2013/03/sql-commands-of-ddl-data-defi…

SQL PRIMARY KEY Constraint
你可以在建立表單時宣告主鍵(primary key),也可以使用ALTER TABLE來建立或是刪除。 CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), PRIMARY KEY (P_Id) ); 你也可以使用以下指令來建立: CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Address varchar(255), City varchar(255), CONSTRAINT pk_PersonID PRIMARY KEY (P_Id) ); 如果Primary key是多欄組成: CREATE TABLE Persons ( P_Id int NOT NULL, LastName varchar(255) NOT NULL, FirstName va…
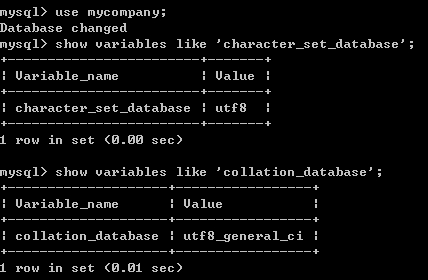
如何使用指令知道資料庫的字元集和排序規則?
假設我們以如下指令新建一個資料庫 CREATE DATABASE mytable CHARACTER SET utf8 COLLATE utf8_general_ci ; 那麼我們就產生了一個資料庫 mytable,並且字元集是 utf8 ,以 utf8_general_ci為排序規則。 但是建立完成之後,過陣子我萬一忘記了字元集跟排序規則的設定,我可以從哪裡知道呢? 你可以使用指令知道資料庫的字元集和排序規則,如下圖。 (1) 你先使用 use mycompany; 開始使用該資料庫。 (2) 以指令 show variables like 'character_set_database' ; 把 mycompany 的字元集資料叫出來。你就看到了字元集是 utf8。 (3) 以指令 show variables like 'collation_database' ; 把 mycompany 的排序規則資料叫出來。你就看到了排序規則是 utf8_general_ci。
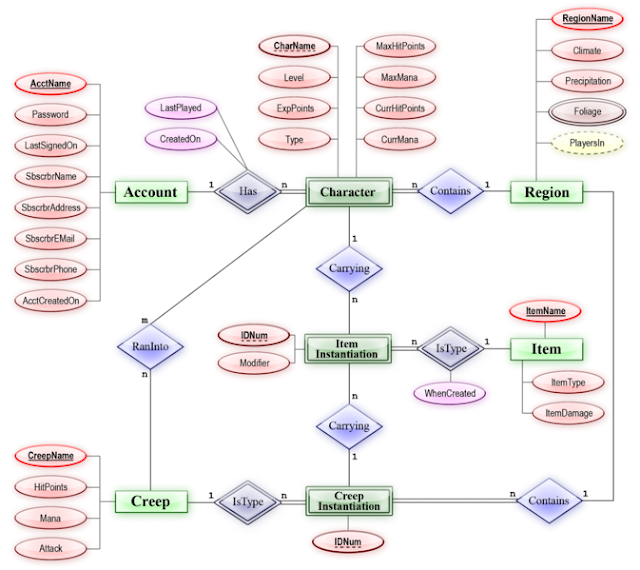
實體關係模型(Entity-relationship model)
實體關係模型 ( Entity-relationship model ) 由美籍華裔計算機科學家陳品山(Peter Chen)發明,是概念數據模型的高層描述所使用的數據模型或模式圖,它為表述這種實體聯繫模式圖形式的數據模型提供了圖形符號。 下圖就是一個ER Model的範例 (可點選放大): 下圖是ER Model常用的符號: 實體(Entity)以長方形表示,實體可以被(粗略地)認為是名詞,如計算機、僱員、歌曲、數學定理。 屬性(Attribute)以橢圓形表示,實體和關聯都可以有屬性,用來代表實體或是關聯外在可以描述的值,例如「國民」這個實體有「身份證字號」這個屬性,「員工」與「公司」間的「雇用」關聯,會有一個「雇用開始日期」屬性。 關聯(Relationship)以菱形表示,關聯描述了兩個或更多實體相互如何關聯。聯繫可以被(粗略地)認為是動詞,如:在公司和計算機之間的擁有關聯,在僱員和部門之間的管理關聯,在演員和歌曲之間的表演關聯,在數學家和定理之間的證明關聯。 弱實體(Weak Entity)以雙線長方形表示,弱實體是指不能獨立存在,必須依靠某個實體而存在的物件。例如訂單品項(order item)就必須跟著訂單(order)而存在,訂單…

資料庫正規化 (normalization)
資料庫正規化 (normalization)的定義: Database normalization is the process of organizing the fields and tables of a relational database to minimize redundancy and dependency. 資料庫正規化就是指把關聯式資料庫的欄位與表單做規劃,讓資料重覆性與相依性能夠降到最低。當然這個"資料重覆性與相依性能夠降到最低"情況下,還必須讓資料庫可以正常運作。 重複的資料 會浪費磁碟空間,並產生維護方面的問題, 不一致的相依性 會讓資料出錯誤。 資料庫正規化有一些規則。每條規則都稱為「正規形式 Normal Form」。如果遵守第一條規則,資料庫就稱為屬於「第一正規形式」。如果遵守前三條規則,資料庫就被視為屬於「第三正規形式」。 雖然可能會有其他層級的正規形式,但第三正規形式被視為大部分應用程式所需的最高階正規形式。雖然有許多正式規則與規格,但真實情況不一定永遠完全都相同。一般而言,正規化需要其他資料表,有些客戶也會嫌麻煩。如果您決定違反正規化前三個原則中的其中一個原則,請確定您的應用程式能夠掌握所有可能發生的問題…

SQL commands of DML (Data Manipulation Language)
DML (Data Manipulation Language)的SQL commands有: (1) SELECT ~ retrieve data from the a database 語法: SELECT [ALL | DISTINCT | DISTINCTROW ] [HIGH_PRIORITY] [STRAIGHT_JOIN] [SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT] [SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS] select_expr [, select_expr ...] [FROM table_references [WHERE where_condition] [GROUP BY {col_name | expr | position} [ASC | DESC], ... [WITH ROLLUP]] [HAVING where_condition] [ORDER BY {col_na…

SQL commands of DDL (Data Definition Language)
DDL (Data Definition Language) 的SQL commands有: (1)CREATE - to create objects in the database 建立資料庫(database) 語法: CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [create_specification] ... create_specification: [DEFAULT] CHARACTER SET [=] charset_name | [DEFAULT] COLLATE [=] collation_name 更多參考: http://dev.mysql.com/doc/refman/5.0/en/create-database.html 例如: CREATE DATABASE mydatabase; 或是 CREATE DATABASE mydatabase CHARACTER SET big5 COLLATE big5_chinese_ci ; 或是 CREATE DATABASE mydatabase CHARACTER SET utf8 CO…

Primary、Unique、Index各代表什麼意義?
在資料表的欄位設定中,你可以設定~ Primary Key = 主鍵、Unique Key = 不重覆鍵、Index Key = 索引鍵,這三個代表的意義是什麼呢? 當你設定一個欄位為Primary Key,也代表這個欄位是not null,並且unique。 如果Primary Key為多欄位組合,例如(id1+id2),這個(id1+id2)也必須是not null & unique。 Primary Key 如下圖,原本可以null的欄位設定成Primary Key 之後,就變成no null,並且Key變成PRI。 其index結構如下圖: 但是如果我們把Primary Key取消,如下圖,PRI不見了,但是仍然是no null。 取消Primary Key之後的index變怎樣呢? 如下圖,index變空的。 要恢復原本的允許null,就必須再下指令,如下圖: Unique Key 當你設定一個欄位為Unique,代表這個欄位不能重覆,但是可以null,如下圖: index變怎樣呢? 如下圖,又有了index結構,表示設成unique,跟設索引是一樣的。 如果我們把Uniqu…